

Author:
(1) Vojtech ˇ Cerm ˇ ak, Czech Technical University in Prague (Email: cermavo3@fel.cvut.cz);
(2) Lukas Picek, University of West Bohemia & INRIA (Email: picekl@kky.zcu.cz/lpicek@inria.cz);
(3) Luka´s Adam, Czech Technical University in Prague (Email: lukas.adam.cr@gmail.com);
(4) Kostas Papafitsoros, Queen Mary University of London (Email: k.papafitsoros@qmul.ac.uk).
Table of Links
- Abstract and Introduction
- Related work
- The WildlifeDatasets toolkit
- MegaDescriptor – Methodology
- Ablation studies
- Performance evaluation
- Conclusion and References
3. The WildlifeDatasets toolkit
One of the current challenges for the advancement of wildlife re-identification methods is the fact that datasets are scattered across the literature and that adopted settings and developed algorithms heavily focus on the species of interest. In order to facilitate the development and testing of reidentification methods across multiple species in scale and evaluate them in a standardized way, we have developed the Wildlife Datasets toolkit consisting of two Python libraries – WildlifeDatasets and WildlifeTools[1] . Both libraries are documented in a user-friendly way; therefore, it is accessible to both animal ecologists and computer vision experts. Users just have to provide the data and select the algorithm. Everything else can be done using the toolkit: extracting and loading data, dataset splitting, identity matching, evaluation, and performance comparisons. Experiments can be done over one or multiple datasets fitting into any used specified category, e.g., size, domain, species, and capturing conditions. Below, we briefly describe the core features and use cases of both libraries.
3.1. All publicly available wildlife datasets at hand
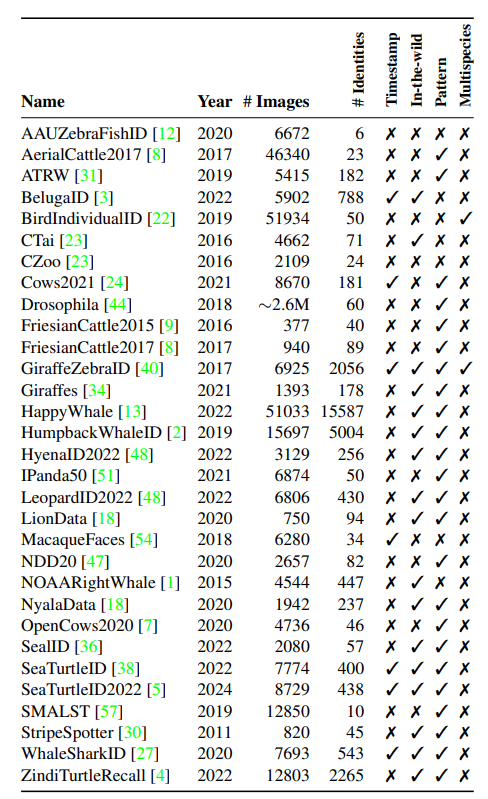
The first core feature of the WildlifeDatasets toolkit allows downloading, extracting, and pre-processing all 31 publicly available wildlife datasets[2] (refer to Table 1) in a unified format using just a few lines of Python code. For reference, see provided code snippet in Figure 2. Additionally, users can quickly overview and compare images of the different datasets and their associated metadata, e.g., image samples, number of identities, timestamp information, presence of segmentation masks/bounding boxes, and general statistics about the datasets. This feature decreases the time necessary for data gathering and pre-processing tremendously. Recognizing the continuous development of the field, we also provide user-friendly options for adding new datasets.
3.2. Implementation of advanced dataset spliting
Apart from the datasets at hand, the toolkit has built-in implementations for all dataset training/validation/test splits corresponding to the different settings, including (i) closedset with the same identities in training and testing sets, (ii) open-set with a fraction of newly introduced identities in testing, and (iii) disjoint-set with different identities in training and testing. In cases where a dataset contains timestamps, we provide so-called time-aware splits where images from the same period are all in either the training or the test set. This results in a more ecologically realistic split where new factors, e.g., individuals and locations, are encountered in the future [38].
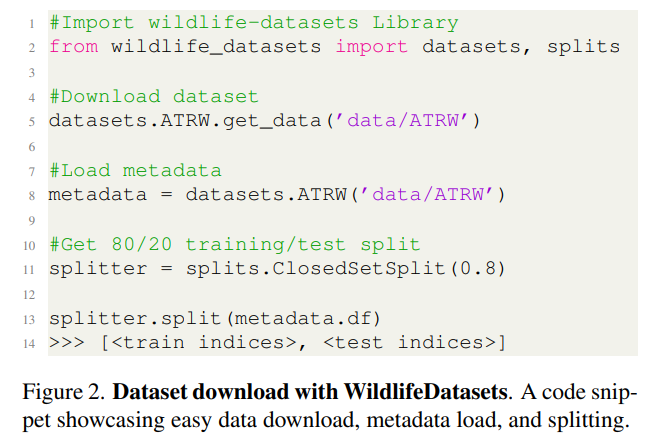
3.3. Accessible feature extraction and matching
Apart from the datasets, the WildlifeDatasets toolkit provides the ability to access multiple feature extraction and matching algorithms easily and to perform re-identification on the spot. We provide a variety of local descriptors, pre-trained CNN- and transformer-based descriptors, and different flavors of the newly proposed foundation model – MegaDescriptor. Below, we provide a short description of all available methods and models.
Local descriptors: Due to extensive utilization among ecologists and state-of-the-art performance in animal reidentification, we have included selected local feature-based descriptors as a baseline solution available for deployment and a direct comparison with other approaches.
Within the toolkit, we have integrated our implementations of standard SIFT and deep learning-based Superpoint descriptors. Besides, we have implemented a matching algorithm that uses local descriptors using contemporary insights and knowledge. Leveraging GPU implementation (FAISS [28]) for nearest neighbor search, we have eliminated the necessity for using approximate neighbors. This alleviates the time-complexity concerns raised by authors of the Hotspotter tool.
Pre-trained deep-descriptors: Besides local descriptors, the toolkit allows to load any pre-trained model available on the HuggingFace hub and to perform feature extraction over any re-identification datasets. We have accomplished this by integrating the Timm library [53], which includes state-of-the-art CNN- and transformer-based architectures, e.g., ConvNeXt [33], ResNext [55], ViT [19], and Swin [32]. This integration enables both the feature extraction and the fine-tuning of models on the wildlife re-identification datasets.
MegaDescriptor: Furthermore, we provide the first-ever foundation model for individual re-identification within a wide range of species – MegaDescriptor – that provides state-of-the-art performance on all datasets and outperforms other pre-trained models such as CLIP and DINOv2 by a significant margin. In order to provide the models to the general public and to allow easy integration with any existing wildlife monitoring applications, we provide multiple MegaDescriptor flavors, e.g., Small, Medium, and Large, see Figure 3 for reference.
Matching: Next, we provide a user-friendly high-level API for matching query and reference sets, i.e., to compute pairwise similarity. Once the matching API is initialized with the identity database, one can simply feed it with images, and the matching API will return the most visually similar identity and appropriate image. For reference, see Figure 4.


3.4. Community-driven extension
Our toolkit is designed to be easily extendable, both in terms of functionality and datasets, and we welcome contributions from the community. In particular, we encourage researchers to contribute their datasets and methods to be included in the WildlifeDataset. The datasets could be used for the development of new methods and will become part of future versions of the MegaDescriptor, enabling its expansion and improvement. This collaborative approach aims to further drive progress in the application of machine learning in ecology. Once introduced in communities such as LILA BC or AI for Conversation Slack[3] , the toolkit has a great potential to revolutionize the field.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
[1] Both libraries are available online on GitHub.
[2] Based on our research at the end of September 2023.
[3] With around 2000 members; experts on ecology and machine learning.