
Authors:
(1) Arindam Mitra;
(2) Luciano Del Corro, work done while at Microsoft;
(3) Shweti Mahajan, work done while at Microsoft;
(4) Andres Codas, denote equal contributions;
(5) Clarisse Simoes, denote equal contributions;
(6) Sahaj Agarwal;
(7) Xuxi Chen, work done while at Microsoft;;
(8) Anastasia Razdaibiedina, work done while at Microsoft;
(9) Erik Jones, work done while at Microsoft;
(10) Kriti Aggarwal, work done while at Microsoft;
(11) Hamid Palangi;
(12) Guoqing Zheng;
(13) Corby Rosset;
(14) Hamed Khanpour;
(15) Ahmed Awadall.
Table of Links
Teaching Orca 2 to be a Cautious Reasoner
B. BigBench-Hard Subtask Metrics
C. Evaluation of Grounding in Abstractive Summarization
F. Illustrative Example from Evaluation Benchmarks and Corresponding Model Outpu
C Evaluation of Grounding in Abstractive Summarization
Fabrication and hallucination is an important challenge for modern LLMs with various aspects of complexity. Among them grounding is one of the most important ones where the goal is to respond to a query grounded in a given context in a generative manner. Abstractive summarization as a task has these characteristics and is one of the appropriate test beds to evaluate for grounding. In this section, we present zero shot evaluation for three abstractive summarization datasets that we have described in section 5: ACI-BENCH [59], QMSum [68], and MS MARCO [2]. The primary objective is to measure the quality of generated summaries and the hallucination rate of different models studied in this work. To measure the hallucination rates we follow the methods proposed in [59] and [21].
C.1 Hallucination Rate Evaluation
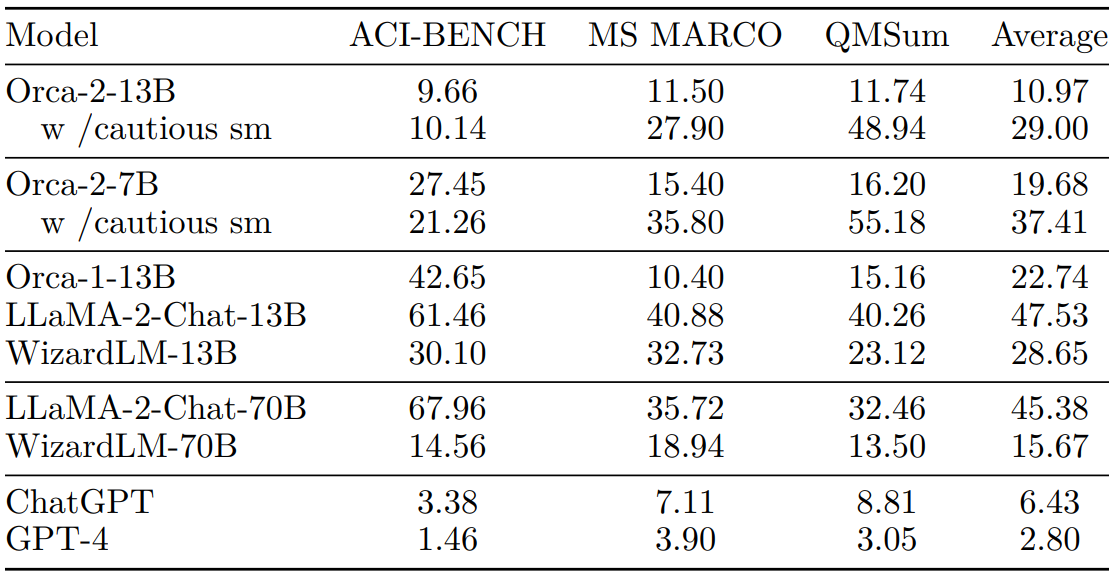
Following the evaluation scheme described in section 6.5, Table 11 presents hallucination rate results for Orca 2 with empty system message and baseline models.
C.2 Evaluation of Generated Summaries
Evaluating the quality of generated summaries with respect to gold summaries requires using both automatic metrics and human evaluation and depending on various evaluation aspects can be quite complex. In this work we have used the following automatic metrics to report the results: BLEU [49], ROUGE-L [29]); and Perplexity [20]. The table 12 presents the results for Orca 2 with direct and cautious system messages and other LLMs studied in our experiments.
For ACI-BENCH Orca 2 shows better performance than both variants of LLAMA 2chat and comparable performance with WizardLM-70B. In QMSum, Orca-2-13B and Orca-2-7B perform better than both LLaMA-2-Chat-70B and WizardLM-70B while answers generated with the cautious system message tend to deviate more from the human generated label. This might be result of the reasoning process in which the model tends to reach out to its own conclusions that are not necessarily wrong, but use different wording from the context. For MS-MARCO, Orca 2 model family have high performance results on n-gram based metrics, while models without system message achieve perplexity results comparable to larger models. Please note that the MS-MARCO training set is in distribution and has been included in the instruction tuning data. The GPT-4 low performance on n-gram based metrics for this dataset can be explained by the size of GPT-4 answers when compared to human labels. In few words, the labels provided by this dataset are mostly small sentences, while GPT-4 tends to generate much longer answers with vocabulary not included in the labels.
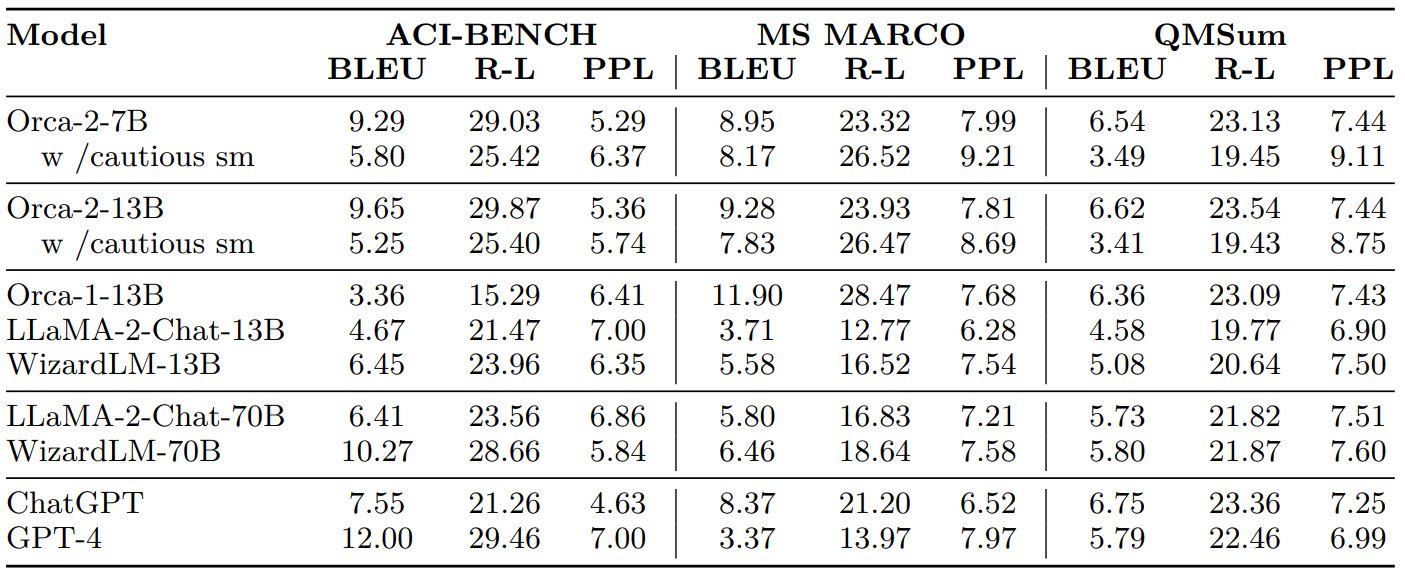
Comparing different versions and system messages of Orca 2 on all datasets, the models using direct system messages tend to perform better than their counterparts using the cautious system message, potentially indicating that answers produced by these models are closer to the ones expected in human-generated summaries. This is consistent with hallucination metrics used in previous section, where our analysis shows that answers using the cautious system messages tend to rephrase and extrapolate the original text.
This paper is available on arxiv under CC 4.0 license.