Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
4.1 Learning Entity Representations from Hyperlinks
4.1.1 Introduction
Entity representations play a key role in numerous important problems including language modeling (Ji et al., 2017), dialogue generation (He et al., 2017), entity linking (Gupta et al., 2017), and story generation (Clark et al., 2018). One successful line of work on learning entity representations has been learning static embeddings: that is, assign a unique vector to each entity in the training data (Yamada et al., 2016; Gupta et al., 2017; Yamada et al., 2017). While these embeddings are useful in many applications, they have the obvious drawback of not accommodating unknown entities.
Motivated by the recent success of contextualized word representations (henceforth: CWRs) from pretrained models (McCann et al., 2017; Peters et al., 2018; Devlin et al., 2019; Yang et al., 2019; Liu et al., 2019), we propose to encode the mention context or the description to dynamically represent an entity. In addition, we perform an in-depth comparison of ELMo and BERT-based embeddings and find that they show different characteristics on different tasks. We analyze each layer of the CWRs and make the following observations:
• The dynamically encoded entity representations show a strong improvement on the entity disambiguation task compared to prior work using static entity embeddings.
• BERT-based entity representations require further supervised training to perform well on downstream tasks, while ELMo-based representations are more capable of performing zero-shot tasks.
• In general, higher layers of ELMo and BERT-based CWRs are more transferable to entity-related tasks.
To further improve contextualized and descriptive entity representations (CER/DER), we leverage natural hyperlink annotations in Wikipedia. We identify effective objectives for incorporating the contextual information in hyperlinks and improve ELMo-based CWRs on a variety of entity related tasks.
4.1.2 Related Work
The training objectives considered in this work are built on previous works that involve reasoning over entities. We give a brief overview of relevant works.
Entity linking is a fundamental task in information extraction with a wealth of literature (He et al., 2013; Guo and Barbosa, 2014; Ling et al., 2015; Huang et al., 2015; Francis-Landau et al., 2016; Le and Titov, 2018; Martins et al., 2019). The goal of this task is to map a mention in context to the corresponding entity in a database. A natural approach is to learn entity representations that enable this mapping. Recent works focused on learning a fixed embedding for each entity using Wikipedia hyperlinks (Yamada et al., 2016; Ganea and Hofmann, 2017; Le and Titov, 2019). Gupta et al. (2017) additionally train context and description embeddings jointly, but this mainly aims to improve the quality of the fixed entity embeddings rather than using the context and description embeddings directly; we find that their context and description encoders perform poorly on EntEval tasks.
A closely related concurrent work by (Logeswaran et al., 2019) jointly encodes a mention in context and an entity description from Wikipedia to perform zero-shot entity linking. In contrast, here we seek to pretrain a general-purpose entity representations that can function well either given or not given entity descriptions or mention contexts.
Other entity-related tasks involve entity typing (Yaghoobzadeh and Schutze ¨ , 2015; Murty et al., 2017; Del Corro et al., 2015; Rabinovich and Klein, 2017; Choi et al., 2018; Onoe and Durrett, 2019; Obeidat et al., 2019) and coreference resolution (Durrett and Klein, 2013; Wiseman et al., 2016; Lee et al., 2017; Webster et al., 2018; Kantor and Globerson, 2019).
4.1.3 Method
We are interested in two approaches: contextualized entity representations (henceforth: CER) and descriptive entity representations (henceforth: DER), both encoding fixed-length vector representations for entities.
The contextualized entity representations encodes an entity based on the context it appears regardless of whether the entity is seen before. The motivation behind contextualized entity representations is that we want an entity encoder that does not depend on entries in a knowledge base, but is capable of inferring knowledge about an entity from the context it appears.
As opposed to contextualized entity representations, descriptive entity representations do rely on entries in Wikipedia. We use a model-specific function f to obtain a fixed-length vector representation from the entity’s textual description.


Encoders for Descriptive Entity Representations. We encode an entity description by treating the entity description as a sentence, and use the average of the hidden states from ELMo as the entity description representation. With BERT, we use the output from the [CLS] token as the description representation.
Hyperlink-Based Training. An entity mentioned in a Wikipedia article is often linked to its Wikipedia page, which provides a useful description of the mentioned entity. The same Wikipedia page may correspond to many different entity mentions. Likewise, the same entity mention may refer to different Wikipedia pages depending on its context. For instance, as shown in Fig. 4.1, based on the context, “France” is linked to the Wikipedia page of “France national football team” instead of the country. The specific entity in the knowledge base can be inferred from the context information. In such cases, we believe Wikipedia provides valuable complementary information to the current pretrained CWRs such as BERT and ELMo.
To incorporate such information during training, we automatically construct a hyperlink-enriched dataset from Wikipedia. Prior work has used similar resources (Singh et al., 2012b; Gupta et al., 2017). The dataset consists of sentences with contextualized entity mentions and their corresponding descriptions obtained via hyperlinked Wikipedia pages. When processing descriptions, we only keep the first 100 word tokens at most as the description of a Wikipedia page; similar truncation has been done in prior work (Gupta et al., 2017). For context sentences, we remove those without hyperlinks from the training data and duplicate those with multiple hyperlinks. We also remove context sentences for which we cannot find matched Wikipedia descriptions. These processing steps result in a training set of approximately 85 million instances and over 3 million unique entities.

Same as the original ELMo, each log loss is approximated with negative sampling (Jean et al., 2015). We write EntELMo to denote the model trained by Eq. (4.1). When using EntELMo for contextualized entity representations and descriptive entity representations, we use it analogously to ELMo.
To evaluate CERs and DERs, we propose a EntEval comprised of a wide range of entity related tasks. Specifically, EntEval consists of the tasks below:
• The task of entity typing (ET) is to assign types to an entity given only the context of the entity mention. ET is context-sensitive, making it an effective approach to probe the knowledge of context encoded in pretrained representations.
• Given two entities and the associated context, coreference arc prediction (CAP) seeks to determine whether they refer to the same entity. Solving this task may require the knowledge of entities.
• The entity factuality prediction (EFP) task involves determining the correctness of statements regarding entities.
• The task of contexualized entity relationship prediction (CERP) modeling determines the connection between two entities appeared in the same context.
• Given two entities with their descriptions from Wikipedia, entity similarity and Relatedness (ESR) is to determine their similarity or relatedness.
• As another popular resource for common knowledge, we propose a entity relationship typing (ERT) task, which uses Freebase (Bollacker et al., 2008) for probing the encoded knowledge by classifying the types of relations between pair of entities.
• Named entity disambiguation (NED) is the task of linking a named-entity mention to its corresponding instance in a knowledge base such as Wikipedia.

4.1.4 Experiments
Setup. As a baseline for hyperlink-based training, we train EntELMo on our constructed dataset with only a bidirectional language model loss. Due to the limitation of computational resources, both variants of EntELMo are trained for one epoch (3 weeks time) with smaller dimensions than ELMo. We set the hidden dimension of each directional LSTM layer to be 600, and project it to 300 dimensions. The resulting vectors from each layer are thus 600 dimensional. We use 1024 as the negative sampling size for each positive word token. For bag-of-words reconstruction, we randomly sample at most 50 word tokens as positive samples from the the target word tokens. Other hyperparameters are the same as ELMo. EntELMo is implemented based on the official ELMo implementation.[1]

We evaluate the transferrability of ELMo, EntELMo, and BERT by using trainable mixing weights for each layer. For ELMo and EntELMo, we follow the recommendation from Peters et al. (2018) to first pass mixing weights through a softmax layer and then multiply the weighted-summed representations by a scalar. For BERT, we find it better to just use unnormalized mixing weights. In addition, we investigate per-layer performance for both models in Section 4.1.5. Code and data are available at https://github.com/ZeweiChu/EntEval.
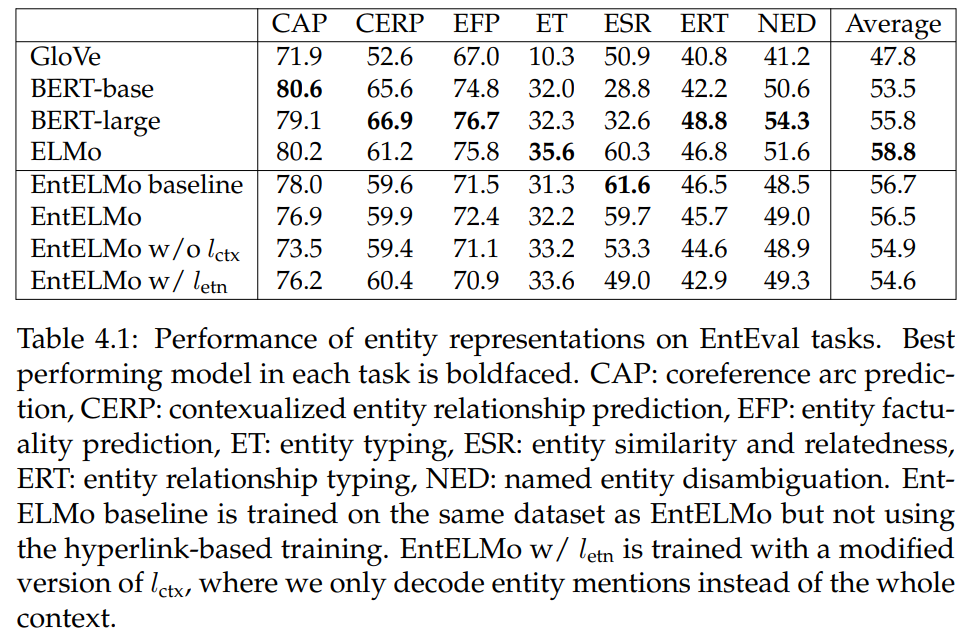
Results. Table 4.1 shows the performance of our models on the EntEval tasks. Our findings are detailed below:
• Pretrained CWRs (ELMo, BERT) perform the best on EntEval overall, indicating that they capture knowledge about entities in contextual mentions or as entity descriptions.
• BERT performs poorly on entity similarity and relatedness tasks. Since this task is zero-shot, it validates the recommended setting of finetuning BERT on downstream tasks, while the embedding of the [CLS] token does not necessarily capture the semantics of the entity.
• BERT-large is better than BERT-base on average, showing large improvements in ERT and NED. To perform well at ERT, a model must either glean particular relationships from pairs of lengthy entity descriptions or else leverage knowledge from pretraining about the entities considered. Relatedly, performance on NED is expected to increase with both the ability to extract knowledge from descriptions and by starting with increased knowledge from pretraining. The Large model appears to be handling these capabilities better than the Base model.
• EntELMo improves over the EntELMo baseline (trained without the hyperlinking loss) on some tasks but suffers on others. The hyperlink-based training helps on CERP, EFP, ET, and NED. Since the hyperlink loss is closely-associated to the NED problem, it is unsurprising that NED performance is improved. Overall, we believe that hyperlink-based training benefits contextualized entity representations but does not benefit descriptive entity representations (see, for example, the drop of nearly 2 points on ESR, which is based solely on descriptive representations). This pattern may be due to the difficulty of using descriptive entity representations to reconstruct their appearing context.
4.1.5 Analysis
Is descriptive entity representation necessary? A natural question to ask is whether the entity description is needed, as for humans, the entity names carry sufficient amount of information for a lot of tasks. To answer this question, we experiment with encoding entity names by the descriptive entity encoder for ERT (entity relationship typing) and NED (named entity disambiguation) tasks. The results
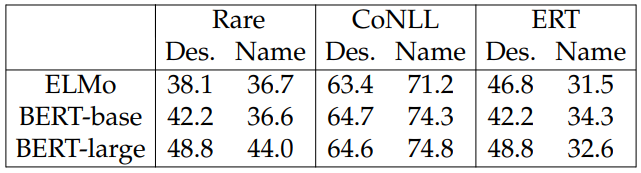
in Table 4.2 show that encoding the entity names by themselves already captures a great deal of knowledge regarding entities, especially for CoNLL-YAGO. However, in tasks like ERT, the entity descriptions are crucial as the names do not reveal enough information to categorize their relationships.
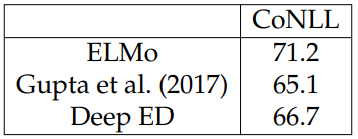
Table 4.3 reports the performance of different descriptive entity representations on the CoNLL-YAGO task. The three models all use ELMo as the context encoder. “ELMo” encodes the entity name with ELMo as descriptive encoder, while both Gupta et al. (2017) and Deep ED (Ganea and Hofmann, 2017) use their trained static entity embeddings. [2] As Gupta et al. (2017) and Deep ED have different embedding sizes from ELMo, we add an extra linear layer after them to map to the same dimension. These two models are designed for entity linking, which gives them potential advantages. Even so, ELMo outperforms them both by a wide margin.
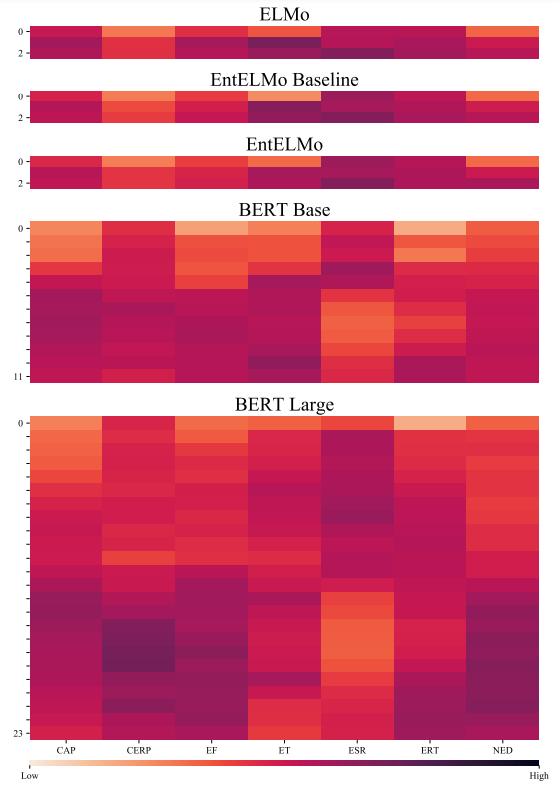
Per-Layer Analysis. We evaluate each ELMo and EntELMo layer, i.e., the character CNN layer and two bidirectional LSTM layers, as well as each BERT layer on the EntEval tasks. Fig. 4.2 reveals that for ELMo models, the first and second LSTM layers capture most of the entity knowledge from context and descriptions. The BERT layers show more diversity. Lower layers perform better on ESR (entity similarity and relatedness), while for other tasks higher layers are more effective.
This paper is available on arxiv under CC 4.0 license.
[1] Our implementation is available at https://github.com/mingdachen/bilm-tf
[2] We note that the numbers reported here are not strictly comparable to the ones in their original paper since we keep all the top 30 candidates from Crosswiki while prior work employs different pruning heuristics.