
Preface
This series will explore the procedure of database anonymization (obfuscation), detailing my experiences and challenges with existing software, and my journey towards implementing a desired open-source project called Greenmask. We will cover terminology, existing software, requirements for the desired solution, internals, and real-world usage of Greenmask for your business cases. Having worked in various roles in the IT industry, from database engineer to product development, I hope to shed light on the needs for database obfuscation. To make the articles more engaging, I will include a question for discussion at the end. Feel free to leave a comment and share your knowledge.
This first article is an introduction to database anonymization. Here, we will discuss:
- Who needs it and what do we gain?
- What is anonymization in simple terms?
- An example of anonymization
The context
I thought about how to provide context for the issue. I don’t believe that starting with terminology and definitions is the best approach. Instead, I decided to present a common example, guide you through the framework, and then pose an engineering question aimed at solving the problem.
Bank employee
Imagine you are working as a software developer at a bank, and you have access only to the testing environment. One day, your project manager approaches you and says, "We have a floating bug for a specific user, and we can’t reproduce it. Could you find a fix in our testing environment?" That’s a tough challenge, but we need to address it somehow. Ideally, your testing database would be properly mocked, allowing you to reproduce the issue. However, in reality, it’s often not that straightforward.
If you don’t have the necessary data, you will either need to generate specific data in the database or request it from those with access to production. When gathering data from production, it’s almost certain you won’t be allowed to use original data samples. Instead, you will receive anonymized data or just instructions on how to configure your testing environment to mimic the production scenario.
Other examples
Outsourcing company: If you are working in an outsourcing company, you might have to navigate through multiple hosts to access data on the client side. I have been in that role, and it often felt like a waste of time. However, you can't imagine how thrilled employees were when our company, in collaboration with our customers, organized a test data management flow. The time-to-delivery improved significantly, and employees were much happier working on that project.
Companies who use outsourcing services: This is another aspect of the previous example. In this scenario, we expose our data to third-party companies for outsourcing services. This poses a significant risk, as it could lead to internal data leakage. To mitigate this, we often deploy numerous barriers to control the actions of outsourcers and prevent data breaches. But what if we could share anonymized data with these outsourcing companies?
AI learning: I believe one key point suffices - the better the quality of the dataset, the better your learning results. It is assumed that the best data quality is found in production, but in many cases, it is not allowed to share this with the development team. In other words, it would be ideal to have data that closely reminds us of production data.
Database anonymization
After having the problem context we can discuss a little about database anonymization terms. I will define the term in simple words.
Database anonymization is a complex and risky process regarding your mission-critical nonpublic data. The main purpose of database anonymization is to transform the original table records but keep the database consistent and valid according to your business logic. The anonymization software must be secure and apply only proper anonymization method (randomization, hashing, filtering, replacing, and subsetting). We will discuss the methods in the next articles.
Synthetic data vs. anonymized data
There is a difference between fully synthetic database data and anonymized database data. Synthetic data is generated independently from the original records, often through a random generator, and without any direct link to the actual values from your production database. Anonymized data instead transforms the original data (mostly production data) in some way using transformers but aims to keep your database consistent and valid for your business logic.
From an information security perspective, both synthetic and anonymized database data should not pose a risk to your company if the data is compromised. There must be no correlation between this data and your real production data, ensuring that hackers cannot use the information to harm your company in any way. However, the probability of having a data leakage through an anonymized production dump is a lot higher than generating a database using synthetic data. That’s why we should pay attention to the anonymization software and methods we are using (random, noise, hash, etc.).
Test Data Management (TDM) platform
Test Data Management (TDM) is the process of creating, managing, and maintaining the data necessary for testing applications throughout the software development lifecycle. TDM ensures that the data used in testing is accurate, relevant, and compliant with regulatory requirements, providing a reliable basis for evaluating the functionality, performance, security, and usability of software applications.
At this point, we are shifting focus to a platform that can control data flows from production to the staging environment. This platform is responsible not only for database transformation and provisioning but also for service deployment.
TDM platform is responsible for:
- Data Creation and Generation (Synthetic or anonymized data)
- Data Subsetting
- Data Refresh and Cloning
- Data Validation and Verification
- Environment Provisioning
- Compliance and Security
- Tooling and Automation
- Data Coverage and Relevance
- Integration with CI/CD Pipelines
- Monitoring and Reporting
By using a test data management approach, we can make data usage safe and private by creating secure copies of real data for testing and analysis purposes, ensuring data protection. This approach reduces blockers in the development process, saving time and securing the process, ultimately improving product quality. Employees can focus on their routine tasks without worrying about the nonexistence of required data. Additionally, we can implement a dynamic sandbox, where proper services in the testing environment run alongside deployed databases with the necessary data provisions.
However, there are drawbacks as well. We need to allocate resources to support the anonymization software, including both human resources and hardware. Additionally, if the database is not properly anonymized, it can still be compromised.
Anonymization example
Now that we've covered the general information, I invite you to explore an example. Let’s take a look at an artificial schema with data that we want to transform. Below is a database schema of two tables: account and order.
CREATE TABLE account
(
id SERIAL PRIMARY KEY,
gender VARCHAR(1) NOT NULL,
email TEXT NOT NULL NOT NULL UNIQUE,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
birth_date DATE,
created_at TIMESTAMP NOT NULL DEFAULT NOW()
);
INSERT INTO account (first_name, gender, last_name, birth_date, email)
VALUES ('John', 'M', 'Smith', '1980-01-01', 'john.smith@gmail.com'),
('Maria', 'F', 'Johnson', '1999-06-03', 'maria.johnson@gmail.com');
CREATE TABLE orders
(
id SERIAL PRIMARY KEY,
account_id INTEGER REFERENCES account (id),
total_price NUMERIC(10, 2),
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
paid_at TIMESTAMP
);
INSERT INTO orders (account_id, total_price, created_at, paid_at)
VALUES (1, 100.50, '2024-05-01', '2024-05-02'),
(1, 200.75, '2024-05-03', NULL),
(2, 53.9, '2023-01-22', NULL);

For each account, there may be zero or more orders. The account table contains personal data such as email, names, and date of birth. The orders table contains a list of account orders with details such as price, a reference to the account table, and the payment date. Imagine you need to share this data in an environment that you don’t fully trust. You need to transform the data while keeping the database consistent and logically correct.
In my point of view, database anonymization can feel like reverse development because it requires careful consideration of your business logic and database schema implementation. Unique constraints, primary keys, foreign keys, and checks play crucial roles in maintaining database consistency, and we must be mindful of these when anonymizing data columns involved in them.
Let’s go back to the table data example and list the hypothetical anonymization rules for the tables.
Account table
idcolumn is unique and is referenced byorderstable- Subset the database and keep the data only for
accound.id = 1 - Generate random
birth_date,first_nameandlast_name first_nameandlast_nameshould be suitable for ourgender(for example, John isMaleand Maria isFemale)emailmust be unique and contain first name and last name separated by a dot (john.smith@gmail.com)created_atmust be after the birth data
Orders table
account_idmust be transformed and have the same value as the transformedaccount.id- the
total_pricemust be noised up to 90% created_atthe date should be randomly generatedpaid_atmust be randomly generated, and the value must be aftercreated_atand do not generate if the value isNULL
This is just an example based on artificial tables with sample data. You can imagine how many corner cases might be found in your production databases. In this simple example, you can see that values in one column may depend on values from another column, which can even be in different tables.
You can find below the transformation result based on the rules we have listed.
That’s for account table
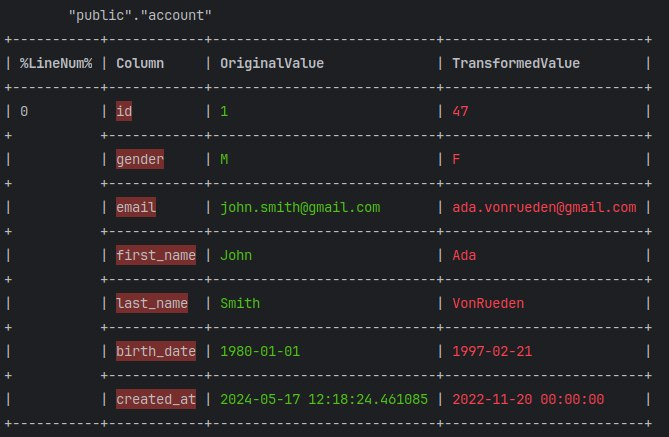
And that’s for orders table
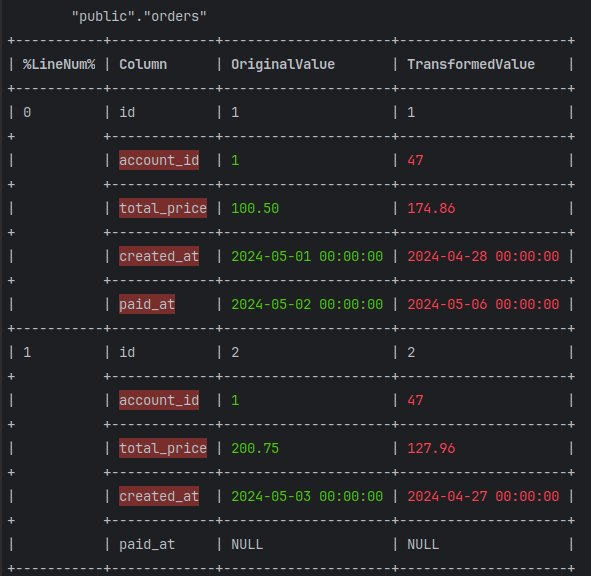
Based on the performed transformation, you can verify that all the changes adhere to the rules listed above. I used Greenmask for the anonymization but deliberately did not publish the configuration, as it is beyond the scope of this article. By the way, if you are really interested in the configuration, I prepared the repository with an example. We will explore Greenmask's usage and internals in future articles.
Afterword and question
In this article, we explored the challenges of database anonymization and the advantages of using data anonymization and test data management in our companies.
I am attaching a link to the Greenmask GitHub repository. Feel free to explore it and share any feedback, even if it's negative. 😉
https://github.com/GreenmaskIO/greenmask?embedable=true
As promised in the preface, here is a question for you:
What would your ideal database anonymization tool look like? Would you prefer a user interface and the ability to implement your transformation business logic?
I will share my opinions and collected requirements, along with explanations, in future articles. Feel free to leave a comment. I would love to hear your experiences and thoughts on this topic. Cheers!