
Authors:
(1) Mingjie Liu, NVIDIA {Equal contribution};
(2) Teodor-Dumitru Ene, NVIDIA {Equal contribution};
(3) Robert Kirby, NVIDIA {Equal contribution};
(4) Chris Cheng, NVIDIA {Equal contribution};
(5) Nathaniel Pinckney, NVIDIA {Equal contribution};
(6) Rongjian Liang, NVIDIA {Equal contribution};
(7) Jonah Alben, NVIDIA;
(8) Himyanshu Anand, NVIDIA;
(9) Sanmitra Banerjee, NVIDIA;
(10) Ismet Bayraktaroglu, NVIDIA;
(11) Bonita Bhaskaran, NVIDIA;
(12) Bryan Catanzaro, NVIDIA;
(13) Arjun Chaudhuri, NVIDIA;
(14) Sharon Clay, NVIDIA;
(15) Bill Dally, NVIDIA;
(16) Laura Dang, NVIDIA;
(17) Parikshit Deshpande, NVIDIA;
(18) Siddhanth Dhodhi, NVIDIA;
(19) Sameer Halepete, NVIDIA;
(20) Eric Hill, NVIDIA;
(21) Jiashang Hu, NVIDIA;
(22) Sumit Jain, NVIDIA;
(23) Brucek Khailany, NVIDIA;
(24) George Kokai, NVIDIA;
(25) Kishor Kunal, NVIDIA;
(26) Xiaowei Li, NVIDIA;
(27) Charley Lind, NVIDIA;
(28) Hao Liu, NVIDIA;
(29) Stuart Oberman, NVIDIA;
(30) Sujeet Omar, NVIDIA;
(31) Sreedhar Pratty, NVIDIA;
(23) Jonathan Raiman, NVIDIA;
(33) Ambar Sarkar, NVIDIA;
(34) Zhengjiang Shao, NVIDIA;
(35) Hanfei Sun, NVIDIA;
(36) Pratik P Suthar, NVIDIA;
(37) Varun Tej, NVIDIA;
(38) Walker Turner, NVIDIA;
(39) Kaizhe Xu, NVIDIA;
(40) Haoxing Ren, NVIDIA.
Table of Links
- Abstract and Intro
- Dataset
- ChipNemo Domain Adaptation Methods
- LLM Applications
- Evaluations
- Discussion
- Related Works
- Conclusions
- Acknowledgments, Contributions and References
- Appendix
V. EVALUATIONS
We evaluate our training methodology and application performance in this section. We study both 7B and 13B models in the training methodology evaluation, and only 13B models in the application performance evaluation. For comparison, we also evaluate two baseline chat models: LLaMA2-13B-Chat* and LLaMA2-70B-Chat. LLaMA2-13B-Chat* is the foundation LLaMA2 13B base model fine-tuned with our general purpose chat instruction dataset, which is different from the original LLaMA2-13B-Chat model trained with reinforcement learning from human feedback (RLHF). We chose to do so for fair comparison of domain adapted models and base models under the same model alignment approach. LLaMA2-70B-Chat is the publicly released LLaMA2-Chat model trained with RLHF, which is considered as the state-of-the-art(SOTA) open-source chat model.
A. Tokenizer
We adapt the LLaMA2 tokenizer (containing 32K tokens) to chip design datasets using the previously outlined four step process. Approximately 9K new tokens are added to the LLaMA2 tokenizer. The adapted tokenizers can improve tokenization efficiency by 1.6% to 3.3% across various chip design datasets as shown in Figure 5. We observe no obvious
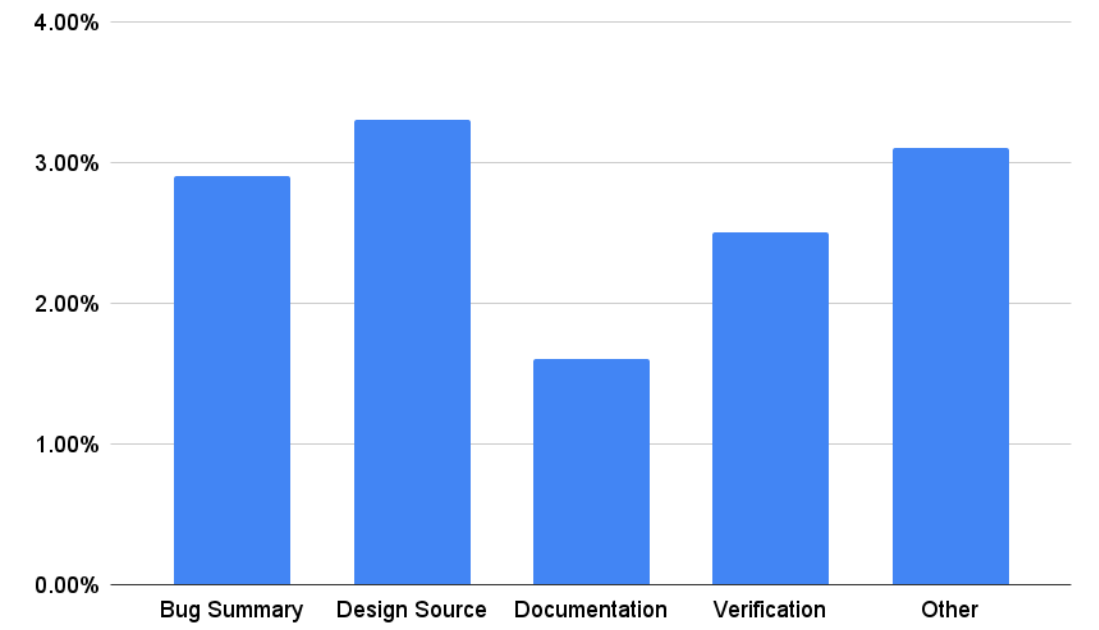
changes to tokenizer efficiency on public data. Importantly, we have not observed significant decline in the LLM’s accuracy on public benchmarks when using the custom augmented tokenizers even prior to DAPT.
B. Domain Adaptive Pretraining
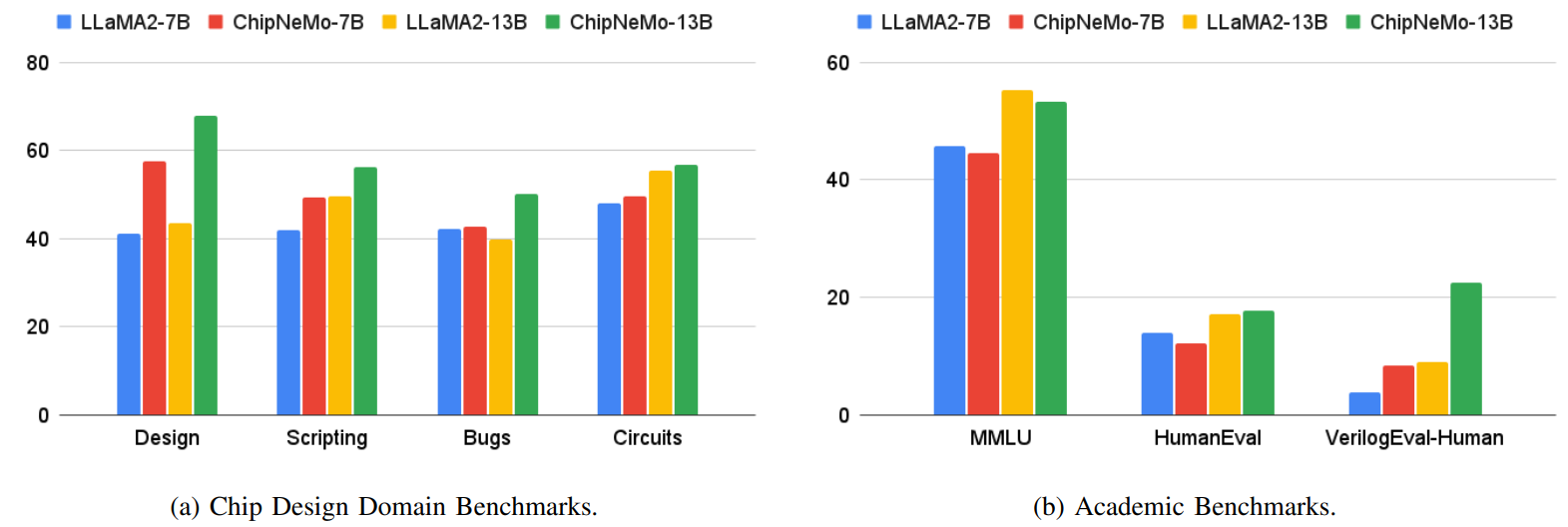
Figure 6 presents the outcomes for ChipNeMo models on the AutoEval benchmark for chip design domain and open domain academic benchmarks. Our research findings can be summarized as follows:
-
DAPT models exhibit a slight degradation in accuracy on open-domain academic benchmarks.
-
DAPT exerts a substantial positive impact on tasks within the domain itself. This effect is manifested in significant improvements in internal design knowledge as well as general circuit design knowledge.
-
The use of larger and more performant foundational models yields better zero-shot results on domain-specific tasks. Furthermore, the employment of superior base models results in enhanced domain models post-DAPT, leading to heightened performance on in-domain tasks.
-
Improvements attributed to DAPT with in-domain tasks exhibit a positive correlation with model size, with larger models demonstrating more pronounced enhancements in domain-specific task performance post-DAPT.
C. Training Ablation Studies
For our ablation studies, we conducted multiple rounds of domain adaptive pre-training. We provide brief summaries and refer to the Appendix B for details.
The differences between training with the augmented tokenizer and the original tokenizer appeared to be negligible. We thus primarily attribute the accuracy degradation on academic benchmarks to domain data. Moreover, the removal of the public dataset only slightly regressed on most tasks including academic benchmarks, with the exception of Verilog coding, where we observed a noticeable difference. This suggests that the inclusion of GitHub Verilog data contributed to enhanced Verilog coding capabilities, particularly when the base foundation models lacked sufficient data in this domain.
In our exploration, we experimented with employing a larger learning rate, as in CodeLLaMA [32]. We observed large spikes in training loss at the initial training steps. Although this approach eventually led to improved training and validation loss, we noted substantial degradations across all domain-specific and academic benchmarks, except on coding. We hypothesize that a smaller learning rate played a dual role, facilitating the distillation of domain knowledge through DAPT while maintaining a balance that did not veer too far from the base model, thus preserving general natural language capabilities.
We also explored the application of Parameter Efficient Fine-Tuning (PEFT) in the context of Domain-Adaptive Pretraining (DAPT). In this pursuit, we conducted two experiments involving the incorporation of LoRA adapters [16], introducing additional parameters of 26.4 million (small) and 211.2 million (large) respectively. In both instances, our findings revealed a significant accuracy gap on in-domain tasks when compared to the full-parameter DAPT approach. Furthermore, when contrasting the outcomes between small and large PEFT models, we observed a marginal enhancement on in-domain task accuracy, with large models exhibiting a slight improvement.
D. Training Cost
All models have undergone training using 128 A100 GPUs. We estimate the costs associated with domain adaptive pretraining for ChipNeMo as illustrated in Table IV. It is worth noting that DAPT accounts for less than 1.5% of the overall cost of pretraining a foundational model from scratch.
![TABLE IV: Training cost of LLaMA2 models in GPU hours. Pretraining cost from [5].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-rk93ukb.png)
E. RAG and Engineering Assistant Chatbot
We created a benchmark to evaluate the performance of design chat assistance, which uses the RAG method. This benchmark includes 88 questions in three categories: architecture/design/verification specifications (Specs), testbench regression documentation (Testbench), and build infrastructure documentation (Build). For each question, we specify the golden answer as well as the paragraphs in the design document that contains the relevant knowledge for the answer. These questions are created by designers manually based on a set of design documents as the data store for retrieval. It includes about 1.8K documents, which were segmented into 67K passages, each about 512 characters.
First, we compare our domain adapted retrieval model with Sentence Transformer [33] and e5_small_unsupervised [30] on each category. Each model fetches its top 8 passages from the data store.
The queries in the Specs category are derived directly from passages in the documents, so their answers are often nicely contained in a concise passage and clearly address the query
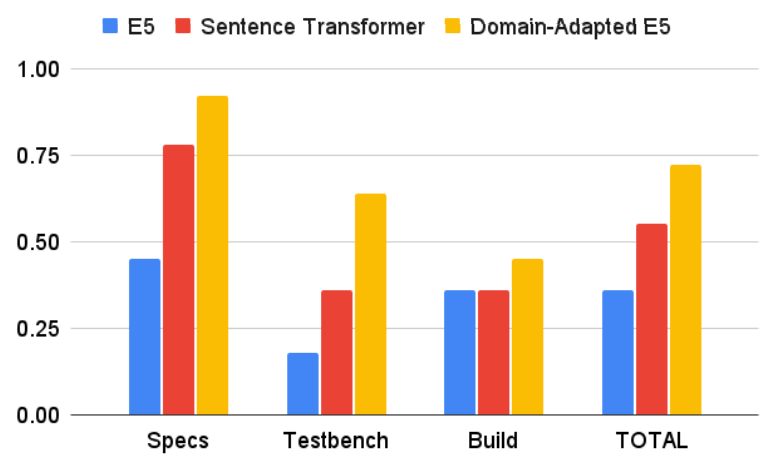
On the other hand, the queries of the Testbench and Build categories are not directly derived from passages, so their answers were often not as apparent in the fetched passages and required more context (see Appendix C for detailed examples). This significantly contributes to the difference in retrieval quality between the categories.
We conducted evaluation of multiple ChipNeMo models and LLaMA2 models with and without RAG. The results were then scored by human evaluators on a 10 point scale and shown in Figure 8.
We made the following observations:
• RAG significantly boosts human scores. RAG improves the scores of LLaMA2-13B-Chat*, ChipNeMo-13B-Chat, and LLaMA2-70B-Chat by 3.82, 2.19, and 5.05, respectively. Note that, scores are generally higher even with RAG miss, particularly on LLaMA2 models. We hypothesize that the additional in-domain context helps to boost the performance.
• ChipNeMo-13B-Chat outperform similar sized LLaMA2- 13B-Chat* in model only and RAG evaluations by 2.88 and 1.25, respectively.
• ChipNeMo-13B-Chat with RAG achieves the same score (7.4) as the 5X larger model LLaMA2-70B-Chat with RAG, where LLaMA2-70B-Chat does better in extracting answers on hits; however, domain adaptation makes up for it on the misses.
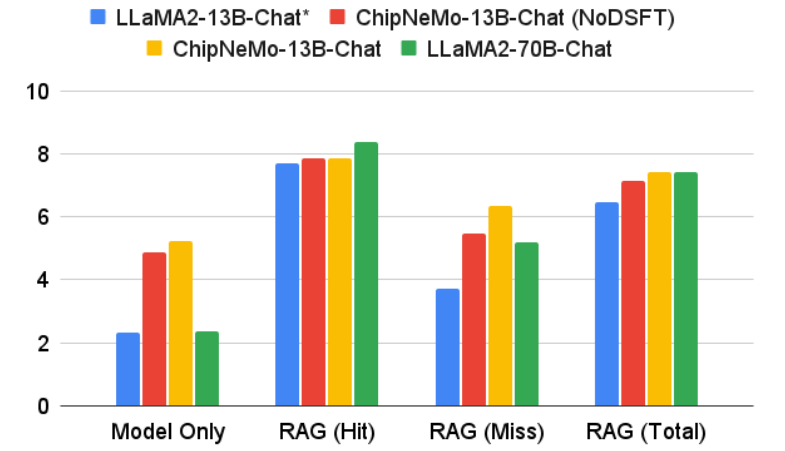
• Domain SFT helps improve the performance of ChipNeMo-13B-Chat by 0.28 (with RAG) and 0.33 (without RAG).
The complete evaluation results on all models are shown in Appendix D.
F. EDA Script Generation
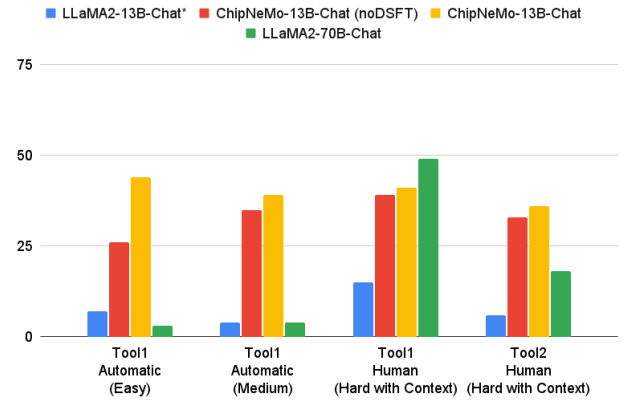
In order to evaluate our model on the EDA script generation task, we created two different types of benchmarks. The first is a set of “Easy” and “Medium” difficulty tasks (1-4 line solutions) that can be evaluated without human intervention by comparing with a golden response. Due to the work required to build and evaluate these benchmarks we only have this evaluation set for our Python task. The second set of tasks (“Hard”) come from real use case scenarios that our engineers chose. These tasks are much harder requiring 10’s of lines to solve. Because these are hard to evaluate in an automatic way, we had human engineers judge the correctness between 0% and 100%. The size of these benchmarks are described in Table V. Work is ongoing to both increase the size and scope for these benchmarks to allow us to further improve these models.
We discovered that our models were unable to answer some of our harder tasks. The tasks required knowledge of many tool APIs and the model seemed to be unable to decide on the proper ones while keeping the control flow properly organized. To mitigate this, we appended a human curated context to the prompt, specific to each question. This context contained explanations of different functions or attributes needed to properly write the desired script. We only provided this for the “Hard with Context” benchmark category. This also allows us to study the possible effect of a retrieval based solution, which we leave to future work.
As can be seen in the ablation results in Figure 9, both DAPT and domain SFT for our problem was important. Without DAPT, the model had little to no understanding of the underlying APIs and performed poorly on automatically evaluated benchmarks. Domain SFT further improved the results. We believe this is because our domain SFT data helps guide the model to present the final script in the most directly applicable fashion.
One interesting result is the LLaMA2-70B pass rate on “Hard with Context” benchmarks. It performs better than most models on the Python tool but poorly on the Tcl tool. This is likely because when provided with the correct context, LLaMA2-70B’s superior general Python coding ability is able to solve novel problems it has not been trained on. However, the LLaMA2-70B model is unable to generalize its coding ability to the Tcl tool, likely because it has not been exposed to a large volume of Tcl code. This highlights the benefit of DAPT when it comes to low-volume or proprietary programming languages.
G. Bug Summarization and Analysis
To evaluate our models on bug summarization and analysis we have a hold out set of 40 bugs which are ideal candidates for summarization. This includes having a long comment history or other data which makes the bugs hard for a human to quickly summarize. We then ask humans to rate both modes of summarization as well as the bug assignment the LLM suggests. The evaluation metric is based on a 7 point Likert scale. Our results are included in Figure 10.

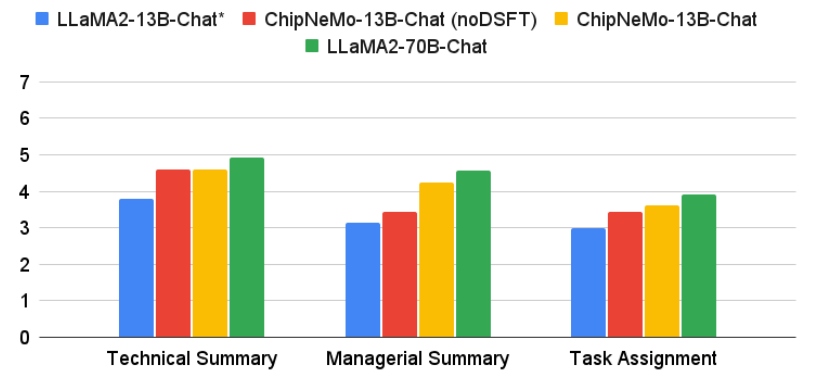
ChipNeMo-13B-Chat models outperform the base LLaMA2- 13B-Chat* model for all three tasks, improving the 7 point Likert score by 0.82, 1.09 and 0.61 for technical summary, managerial summary and assignment recommendation, respectively. Domain SFT also significantly improves the performances over without domain SFT on managerial summarization and task assignment.
We hypothesize that contrary to the technical summarization task whose quality and technical content are more dependent on the model’s understanding of natural language semantics, managerial summary requires the model to understand how to summarize the input data while retaining key personnel/engineer names. This needs a more careful instruction-based finetuning of the LLM.
LLaMA2-70B-Chat model also performs very well on all three tasks, beating ChipNeMo-13B model over all tasks. Note that LLaMA2-70B-Chat model also suffers from long-context challenges with 4096 context size, we believe effective chunkand-combine schemes (hierarchical and incremental), choice of instructional prompts at various stages of summarization, choice of prompt during task assignment, and raw data formatting/preprocessing help in circumventing the long-context challenge and enable LLaMA2-70B-Chat to achieve high scores even without DAPT and domain SFT.
This paper is available on arxiv under CC 4.0 license.