Authors:
(1) Ángel Merino, Department of Telematic Engineering Universidad Carlos III de Madrid {angel.merino@uc3m.es};
(2) José González-Cabañas, UC3M-Santander Big Data Institute {jose.gonzalez.cabanas@uc3m.es}
(3) Ángel Cuevas, Department of Telematic Engineering Universidad Carlos III de Madrid & UC3M-Santander Big Data Institute {acrumin@it.uc3m.es};
(4) Rubén Cuevas, Department of Telematic Engineering Universidad Carlos III de Madrid & UC3M-Santander Big Data Institute {rcuevas@it.uc3m.es}.
Table of Links
LinkedIn Advertising Platform Background
Nanotargeting proof of concept
Ethics and legal considerations
Conclusions, Acknowledgments, and References
ABSTRACT
A body of literature has shown multiple times that combining a few non-Personal Identifiable Information (non-PII) items is enough to make a user unique in a dataset including millions or even hundreds of millions of users. This work extends this area of research, demonstrating that a combination of a few non-PII publicly available attributes can be activated by a third party to individually target a user with hyper-personalized messages. This paper first implements a methodology demonstrating that the combination of the location and 6 rare (or 14 random) professional skills reported by a user in their LinkedIn profile is enough to become unique in a user base formed by ∼800M users with a probability of 75%. A novel feature in this case, compared to previous works in the literature, is that the location and skills reported in a LinkedIn profile are publicly accessible to any other user or company registered in the platform and, in addition, can be activated through advertising campaigns. We ran a proof of concept experiment targeting three of the paper’s authors. We demonstrated that all the ad campaigns configured with the location and ≥13 random professional skills retrieved from the authors’ LinkedIn profiles successfully delivered ads exclusively to the targeted user. This practice is referred to as nanotargeting and may expose LinkedIn users to potential privacy and security risks such as malvertising or manipulation.
Keywords LinkedIn · Online advertising · User privacy · Nanotargeting
1 Introduction
The ability of third parties to uniquely identify users without their consent at scale is a good thermometer of how fragile citizens’ privacy is. An obvious way to identify a user is through Personal Identifiable Information (PII) such as email, phone number, postal address, etc. Creating large unlawful databases of PII may represent privacy risks for the users. That is why frequent awareness campaigns instruct users to be careful with emails, SMS, WhatsApp messages, etc., coming from unknown sources. In fact, current data protection regulations such as the GDPR [1] clearly state that PII is personal data and requires (in most cases) the user’s consent to be processed. A more subtle approach to uniquely identify and potentially target a user is combining multiple non-PII items that are not considered personal data in isolation. This identification based on non-PII is harder to detect but poses a significant risk. This is why user uniqueness based on non-PII data has been addressed in the literature in recent years.
The research literature has repeatedly proven that few non-PII items are enough to identify a user in large datasets uniquely. For example, just 4 mobile phone call records can identify a user in a dataset of 1.5 million users [2]. Similarly, in a user base of 1.1 million users, only 4 credit card purchase records are needed to single out an individual [3].
Likewise, 8 movie ratings and approximate review dates can single out a user among 480k Netflix users [4]. Combining gender, zip code, and birth date can reveal the identities of 87% and 63% of citizens in the 1990 and 2000 US censuses, respectively [5][6]. Also, 15 demographic attributes can re-identify 99.98% of Americans in any dataset [7].
These studies represent an invaluable contribution to assessing the fragility of human privacy. However, all those works remain theoretical and do not discuss how the non-PII data items can be activated in specific attacks compromising users’ security and/or privacy. We believe the natural step forward to complete this area of research is developing methodologies and experiments to demonstrate that the combination of non-PII items can be activated in practice by third-party to target users individually and (potentially) compromise their security and/or privacy.
To the best of the authors’ knowledge, the only prior study in the field that practically shows that a combination of non-PII items can be activated to reach a single user exclusively with an ad is [8]. This work performs a proof of concept experiment, showing that an attacker being able to unveil ∼20 random ad preferences from a user can target them with a nanotargeting ad campaign, i.e., the ad reaches the targeted user exclusively. This is the first tangible proof that non-PII information can be exploited to target individual users without explicit consent to be reached uniquely by those means. However, the practical use of the reported technique at scale has a significant limitation. It requires the attacker to access users’ ad preferences, which is a complex task since they are not publicly available. This limitation reduces the potential attackers to those with strong technical knowledge able to infer the ad preferences of a user. Although the referred work is a very important research contribution, we believe it is important that the research community contributes further studies showing that it is feasible to implement hyper-personalized attacks subject to publicly available non-PII items proactively disclosed by users. Such studies would prove that non-PII items, often not considered personal data, may involve severe privacy and/or security risks for users.
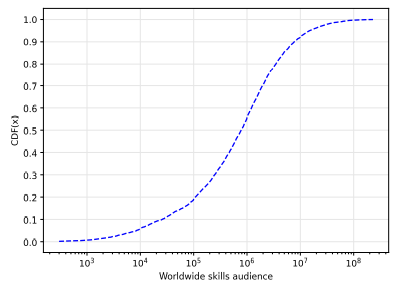
Our work shows that hundreds of millions of users may be individually targeted with hyper-personalized messages combining a few non-PII publicly available data items. To this end, in this research, we imposed ourselves three requirements: (i) the user base should include tens or hundreds of millions of users distributed all over the world; (ii) the non-PII data items required to target an individual user must be publicly available, and (iii) the non-PII items can be activated by external third-parties to reach users with hyper-personalized messages individually. To the best of our knowledge, none of the previous works in the literature meets these three requirements simultaneously.
Our paper proves that an individual user can be nanotargeted on LinkedIn with an ad using the combination of the location (country, region, or city) and the professional skills available in their profile. This meets the three previous requirements as follows: (i) LinkedIn has ∼800 million users, i.e., roughly 10% of the worldwide population is available, (ii) the location and professional skills of its users are publicly available non-PII items to anyone logged on LinkedIn. Hence, anyone can easily obtain the required information that uniquely identifies a user on LinkedIn, and (iii) the combination of professional skills and location can be activated through the LinkedIn Ads Manager to deliver hyper-personalized ads to the users. In practice, this means that nanotargeting a user just requires having a LinkedIn account, retrieving the location and professional skills from the targeted user profile, and configuring an ad campaign using that information. This is a very simple operation that may enable many third parties willing to do so to run nanotargeting campaigns/attacks on LinkedIn exploiting non-PII items.
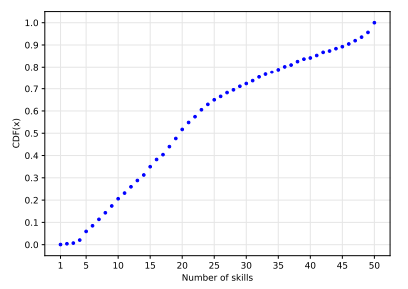
We divided our work into two parts. In the first part of the paper, we use a dataset including information on 39k skills collected from 1699 users, and we develop a data-driven model that defines the probability of user uniqueness on LinkedIn by combining the location and N professional skills publicly available in their profile. In the second part of the paper, we use the model’s outcome to implement a proof of concept experiment, targeting three authors of this paper, demonstrating that it is feasible to run nanotargeting campaigns on LinkedIn.
LinkedIn claims in its advertising guidelines that the minimum number of targeted members to launch a campaign is 300, but this limit can be bypassed easily by exploiting what we believe is an implementation bug. We reported the privacy vulnerability unveiled by our research to LinkedIn following their recommended process. Unfortunately, the platform managers who received our report did not consider our research results represents a vulnerability.
This work has yielded several key findings:
• Combining users’ location with 14 (23) randomly selected skills from their reported skill set makes them unique on LinkedIn with a 75% (90%) probability. If we use the least popular skills instead, we only need 6 (8) skills to achieve the same level of uniqueness.
• Our proof of concept experiment shows that all campaigns using the location and ≥13 random skills successfully nanotargeted the three targeted authors.
• To the best of our knowledge, this is the first study showing proof that publicly available non-PII data can be used to effectively target unique citizens at scale.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.